
工作动态
当前预训练大语言模型的蓬勃发展为面向科学文献的领域NLP(Natural Language Processing , NLP)任务带来了新的前景。我中心大数据部与国家纳米科学中心合作,构建了大模型增强的电催化还原和合成过程的开源数据集,帮助催化领域科学家快速发现新型高效催化剂并完成制备,同时发布了基于电催化领域文献预训练和标注数据指令微调后的大模型参数,为催化材料领域的其他生成式任务提供模型支持。该研究成果在Nature数据子刊Scientific Data上发表。大数据部陈雪青、王露笛为论文共同第一作者,杜一研究员为论文共同通讯作者。
该成果得到重点研发计划青年科学家项目“基于领域知识图谱的光电催化材料挖掘软件”以及国家基础学科公共科学数据中心等项目的支持。
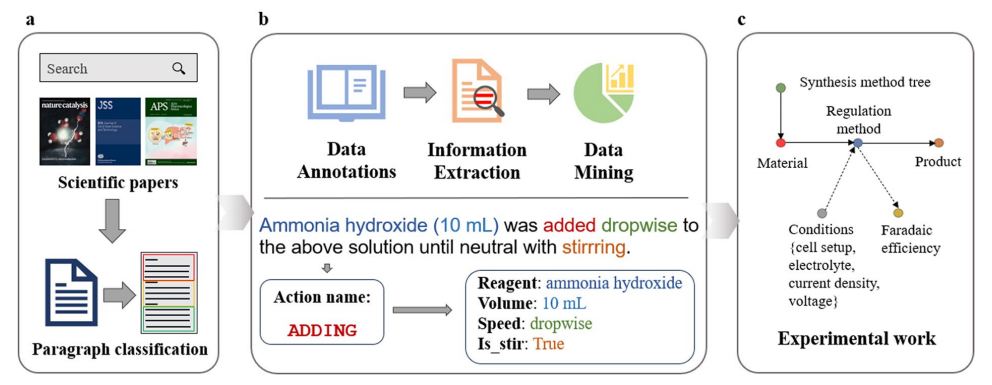
语料库构建的整体框架及合成过程拆解流程
论文链接:
https://www.nature.com/articles/s41597-024-03180-9
数据库链接:
https://doi.org/10.57760/sciencedb.13290;
https://doi.org/10.57760/sciencedb.132924;
https://doi.org/10.57760/sciencedb.13293。
责任编辑:郎杨琴
附件下载