
大数据软件栈弹性部署与管理
针对大数据软件栈带来的部署困难、配置复杂等问题,研究基于Master+Slave+Client的统一部署与水平扩展模式,研究基于私有云、公有云、混合云的部署技术,研究全生命周期的Serverless数据管理服务模型与框架。
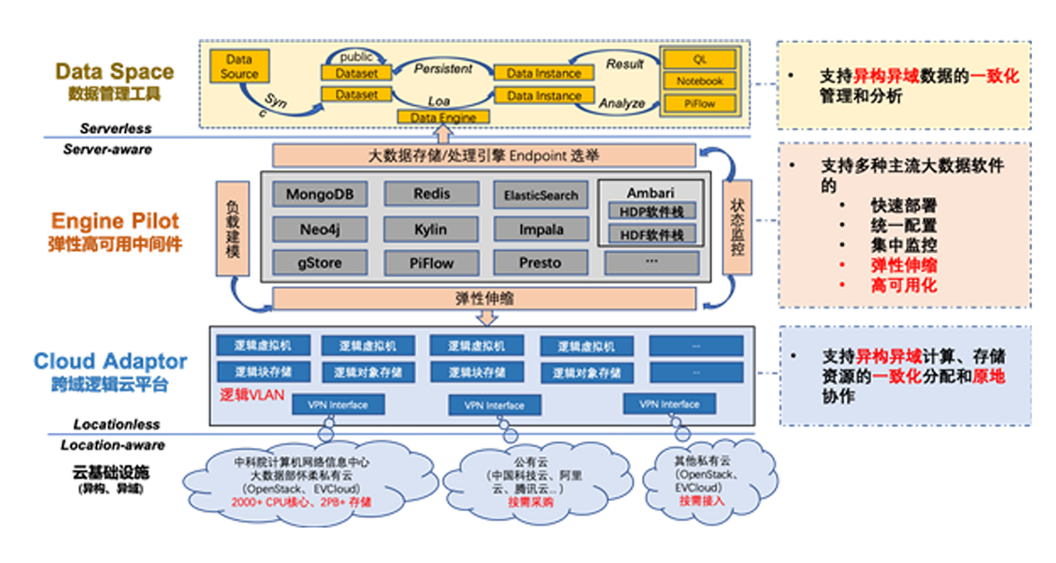
研发PackOne系统,目前版本可实现20+类主流大数据组件的“一键部署”和水平扩展配置,支持OpenStack和EVCloud,支持Impala、SolrCloud、Kylin、Neo4j等

配置化可溯源大数据流水线管理
面向大数据多元采集与加工清洗需求,针对大数据的流动性特征,研究设计大数据流水线表征模型,设计可溯源、可监控的流水线执行引擎,设计流水线执行的监控机制和故障恢复方法。

研发PiFlow系统,目前版本具有如下特性:
1、易用性提供所见即所得的Web界面配置流水线,非常直观地监控流水线状态,查看流水线日志,同时提供检查点功能。
2、扩展性强支持用户自定义开发组件,满足用户的特定需求。
3、性能优越原生支持分布式计算引擎Spark,与国际主流工具NiFi比较,性能提升3倍以上。
4、功能强大提供100+个数据处理组件,包括Hive、Hbase、Solr、Redis、Memcached、ElasticSearch、JDBC、MongoDB、HTTP、FTP、XML、CSV、JSON数据处理,以及机器学习、图分析算法等。
大规模多元异构数据融合管理
针对大规模的结构化/非结构化数据的一体化存储问题,研究设计高效的存储结构和存储事务引擎,设计原生支持blob属性的数据查询语言,实现对非结构化属性的查询和流式读写;针对非结构化数据的信息抽取和在线查询问题,设计并定义面向非结构化数据的语义计算操作符,设计数据查询引擎,实现对AI计算的原生支持。
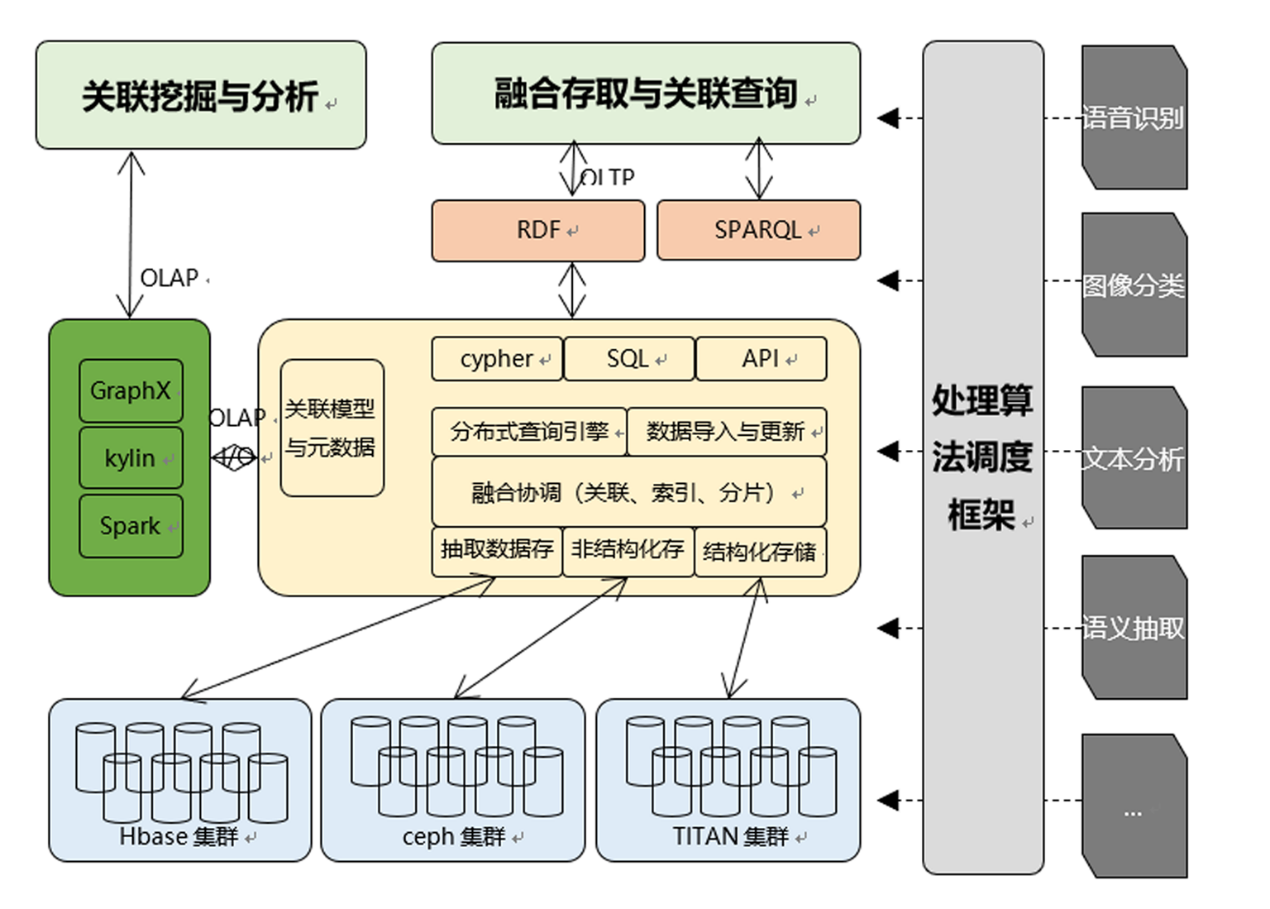
研发PiDB系统,目前可支持亿级文件和百亿级属性的存储,同时构建可扩展、易部署的AI库管理模块AIPM,实现人脸识别、情感分类等AI计算的服务化与集成查询。
相关专利
一种支持非结构化数据存储与查询的图数据库管理系统 -201811202708X一种支持BLOB的多元大数据融合方法和系统 - 201710321988.5一种基于图遍历的SPARQL查询优化方法 - 201710343003.9一种融合图数据库和人工智能算法的数据管理方法及系统 -201811212493X一种扩展、组织和使用图数据属性和语义信息的方法
领域知识图谱关键技术研发与应用
在大数据基础环境支撑下,利用分布式大数据采集与融合技术,设计一整套领域知识图谱构建流水线。以科技领域为切入点,突破大规模网络数据存储、实体发现与链接预测、行业趋势与交叉学科预测等关键技术,构建科技领域知识图谱。



领域应用
烟草科技知识图谱服务平台
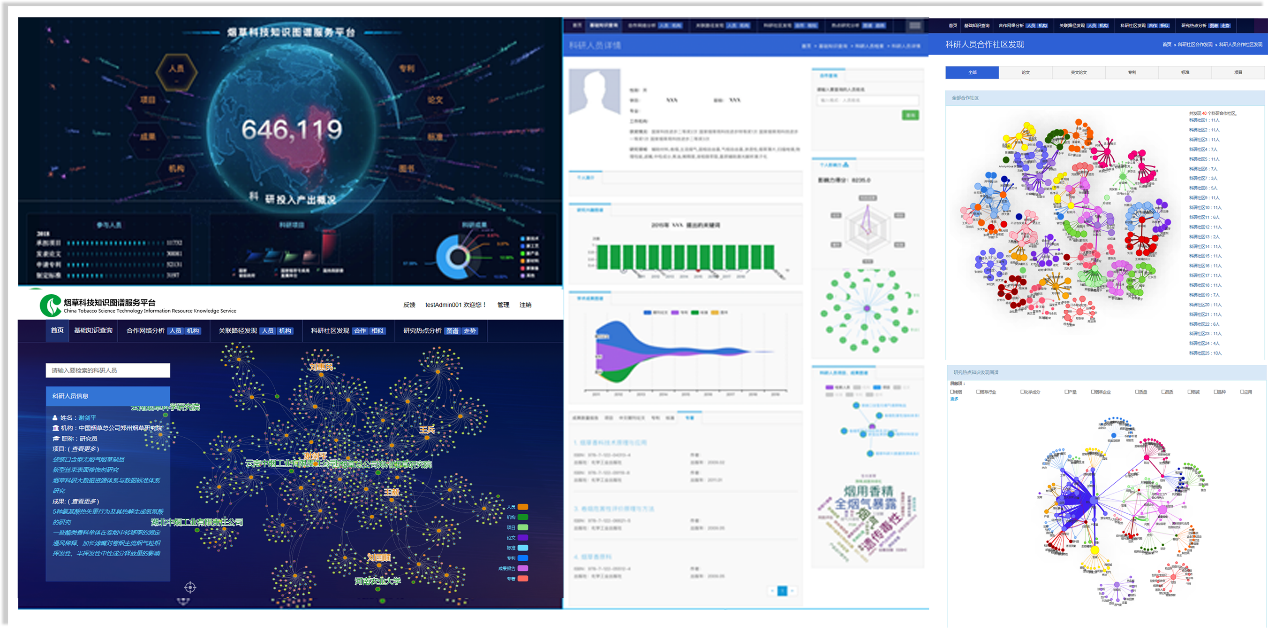
国家自然科学基金大数据知识管理服务平台
