
工作动态
针对大规模撕裂有限元相关科学计算中批量稠密矩阵向量乘算子计算效率低和负载不均衡问题,我中心提出了多流流水并行策略、批量胖矩阵运算优化和多粒度智能负载均衡方法,与中国原子能科学研究院合作,在国产超级计算系统上实现中国实验快堆全堆芯百亿网格稳态分析,其弱可扩展效率和强可扩展效率分别达到78%和72%。该研究成果被国际顶级会议ACM SIGPLAN Annual Symposium Principles and Practice of Parallel Programming(PPoPP,CCF A类)2023录用。我中心人工智能部客座学生林克豪和周纯葆副研究员为共同第一作者,王珏正高级工程师为通信作者。
大规模撕裂有限元算法中需要批量处理的核心算子包括不同大小稠密矩阵向量乘和胖矩阵向量乘。团队针对国产加速器上不同大小稠密矩阵向量乘算子的多流流水并行批处理操作进行了优化,带来了15%~30%的吞吐量提升。优化了胖矩阵向量乘算子的核函数,平均性能提升达30%。
多粒度智能负载均衡方法分为粗粒度和细粒度两个阶段:粗粒度阶段通过运行时信息进行大规模图重划分将计算负载不均衡率从1.5降低到1.15~1.20;细粒度阶段通过动态工作窃取技术将负载不均衡率进一步降低到1.05~1.09。该负载均衡策略不仅可以进一步应用到全堆芯动力学仿真,而且可以针对大规模图神经网络训练进行性能优化。
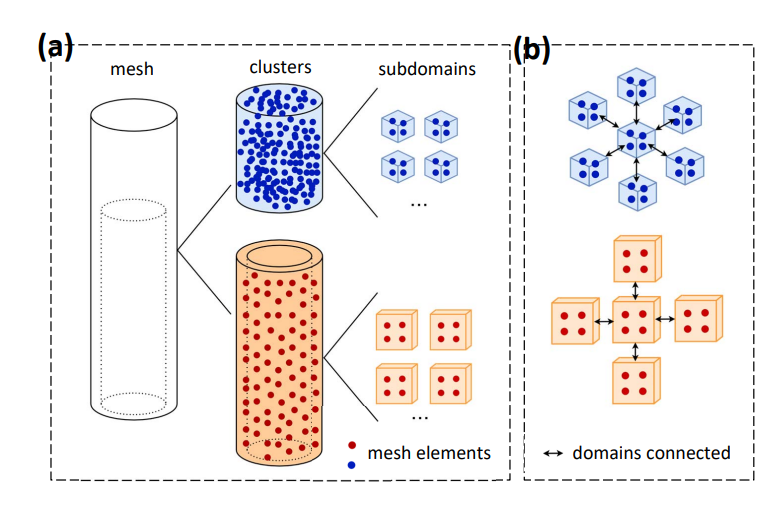
图1 (a)两级分解:一个底部中空的棒被分成两个簇;每个簇被分成多个子域 (b)子域及其相关的连接子域
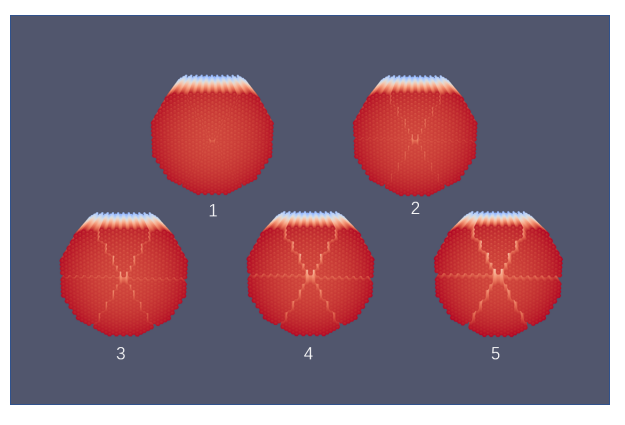
图2 中国实验快堆静力学分析结果
该成果得到国家重点研发计划“数值反应堆原型系统开发及示范应用”项目的支持。人工智能团队承担其中E级优化关键技术课题。(撰稿人:王珏、周纯葆)
相关成果:
Kehao Lin, Chunbao Zhou, Yan Zeng, Ningming Nie, Jue Wang*, Shigang Li, Yangde Feng, Yangang Wang, et al., A Scalable Hybrid Total
FETI Method for Massively Parallel FEM Simulations, ACM SIGPLAN Annual Symposium Principles and Practice of Parallel Programming(PPoPP) 2023
附件下载